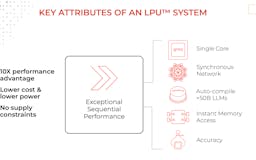
A new type of end-to-end processing unit system that provides the fastest inference for computationally intensive applications with a sequential component to them, such as AI language applications (LLMs)
An LPU Inference Engine, with LPU standing for Language Processing Unit™, is a new type of end-to-end processing unit system that provides the fastest inference at ~500 tokens/second.
Groq Chat
This alpha demo lets you experience ultra-low latency performance using the foundational LLM, Llama 2 70B (created by Meta AI), running on the Groq LPU™ Inference Engine.