

Cekura
Automated QA for Voice AI and Chat AI agents
1.9K followers
Automated QA for Voice AI and Chat AI agents
1.9K followers
Cekura enables Conversational AI teams to automate QA across the entire agent lifecycle—from pre-production simulation and evaluation to monitoring of production calls. We also support seamless integration into CI/CD pipelines, ensuring consistent quality and reliability at every stage of development and deployment.
This is the 3rd launch from Cekura. View more
Cekura
Launched this week
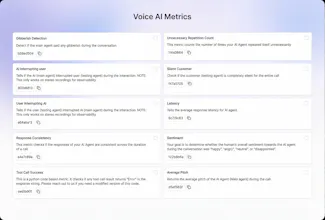
Out-of-the-box 30+ predefined metrics for analysis on CX, accuracy, conversation and voice quality. Compile perfect LLM judges by annotating just ~20 conversations and auto-improve in Cekura labs. Real-time, segmented dashboards to identify trends in Conversational AI. Smart statistical alerts so that you get notified only when metrics shift from historical baselines. Automated system pings to catch silent production failures.



Free Options
Launch Team / Built With







Cekura
Hi Product Hunt! 👋
We are excited to launch Cekura Monitoring for Voice and Chat AI companies. Most monitoring tools tell you if your AI is up. Cekura tells you if it is behaving.
When we had first launched Cekura QA, we thought we had solved the problem for both testing and monitoring . But as our users scaled, we noticed a painful pattern: While pre-production QA was automated, teams were still spending dozens of hours manually listening to thousands of calls.
The two big blockers we saw were:
The Scaling Wall: Defining and optimizing custom metrics was taking too long, forcing teams back into manual spot-checks.
Production Blindspot: Standard LLM metrics misses the Customer Experience in Voice AI - things like agent tone and customer sentiment that actually defines customer success.
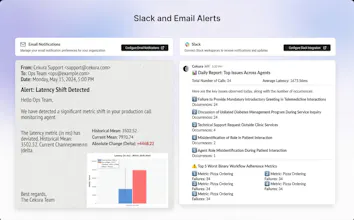
We have rebuilt the monitoring layer from the ground up to solve this. Cekura Monitoring turns that "wall of noisy logs" into actionable signals.
🚀 What’s New in Cekura Monitoring:
30+ Predefined Metric Suite: We track what actually breaks Voice and Chat agents across four critical categories:
Speech Quality: Voice clarity, pronunciation, and gibberish detection.
Conversational Flow: Silences, interruptions (barge-ins), and termination triggers.
Accuracy & Logic: Hallucinations, transcription accuracy, and relevancy.
Customer Experience: CSAT, Sentiment analysis, and drop-off points.
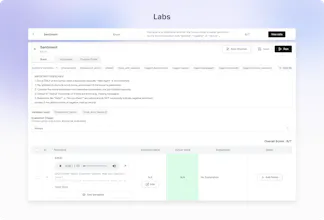
Metric Optimizer: Stop "vibes-based" prompt engineering. Define a metric (e.g., Successful User Authentication), tag 20 calls in our Labs interface, and our optimizer "compiles" a prompt that aligns with your specific feedback.
Statistical Intelligence: No more fixed, noisy thresholds. Our Alerting Engine learns your agent's baseline and only pings Slack when metrics shift 2σ from historical norms.
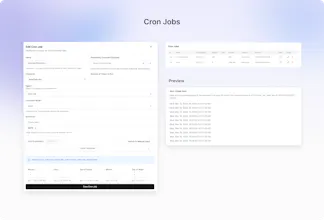
Automated Cron Jobs: Set up recurring health checks to simulate production conversations. Catch silent failures and regressions before your customers do.
Visual Dashboards: Real-time distribution charts for each metric. Views customized for each stakeholder
Who is this for?
Teams scaling Voice & Chat AI who are tired of listening to calls manually and need a way to prove their agents are actually working.
Sign up and try for free at cekura.ai or drop your questions below! We would love to hear how you’re currently handling Voice and Chat AI in production👇
@kabra_sidhant Many congratulations on the launch, Sidhant! I've been tracking it since the Vocera days, it's evolved impressively and keeps getting better. Thrilled to see the buzz in voice AI communities especially on Reddit. Onwards and upwards! :)
Cekura
@rohanrecommends Thanks Rohan - also for all your guidance on best practices for Product Hunt Launches!
DaoLens
How are you different from tracing platforms like Braintrust and Galileo ? Except Voice metrics.
Cekura
@nimishg We are E2E conversational AI QA - Some of the big differences:
We run E2E multi turn simulations instead of trace level logging
These platforms does not offer Metric optimizer - without metric optimizer, it takes huge time to fine tune LLM-as-a-judge metrics
We also offer replay of production conversations to ensure the fix is incorporated.
In short we are very deep and verticalized in Conversational AI evals - they are more horizontal general agentic AI evals platforms
Cekura
@nimishg Braintrust/galileo are very horizontal for all llm agents. We are specialised for conversations, our UI, Metrics, dashboards are highly specialised for conversations.
What aspects of voice does it capture? I wanted to test on tonality and personality of my voice agent, is it achievable?
Cekura
@pratyush1505 We have voice clairty, gibberishness as a metric to capture the voice aspect of the agent
Cekura
@pratyush1505 For testing the personality of the agent, you can also checkout the Customer Satisfaction (CSAT) and Sentiment metrics
Cekura
@pratyush1505 you can also use voice clarity metric which will check how clear the voice is
The "is it behaving" vs "is it up" distinction is spot on. We've had AI chat agents pass every health check while giving completely wrong answers to customers. Uptime metrics are useless if the AI is confidently hallucinating.
How granular does the sentiment tracking get? Like can it detect when an agent starts being passive aggressive or gives a technically correct but unhelpful response? That's the stuff that kills user trust slowly.
Cekura
@mihir_kanzariya We are currently building turn level sentiment tracking - should be live in a week's time. Currently it gives overall sentiment score but granular feedback on where sentiment turned negative.
We have a metric called relevancy which test whether the agent response is relevant to the user question or not
Cekura
@mihir_kanzariya Sentiment analysis can be made as specific as you want. Our pre-defined metric has 3 states: neutral, positive, negative. But it is very seamless to tune this metric and have many other states. You should be able to create a highly accurate custom metric within 5 mins
This is something we've been looking for. We deploy voice and chat AI agents for businesses (support, qualification, scheduling) and QA has always been the manual bottleneck — listening to call recordings, checking if the agent followed the script, catching edge cases.
The 30+ predefined metrics and CI/CD integration is exactly what's needed to ship agent updates with confidence. Do you support Vapi-based voice agents out of the box, or does it require custom integration?
Cekura
@ksagachev Yes, Vapi is supported out of the box, no custom integration needed. Takes <5 min to setup.
Cekura
@ksagachev We have a very deep integration with vapi. It should feel seemless
Cekura
@ksagachev We have a native integration with Vapi for sending production conversations, tool calls and to run outbound simulations automatically
Is the metrics customizable ? For example I need to define success criteria by peak latency and not mean latency
Cekura
@rishav_mishra3 Yes, Cekura is modular in a way that lets you go from full automation to full control, depending on your needs.
One of our key features is Python based metrics with access to all processed data, so you can measure exactly what you care about, like peak latency instead of mean latency. We also support defining your own success criteria using a flexible rubric style configuration.
Cekura
@rishav_mishra3 yes they are customisable. We expose the code of our latency metric which you can customise to get peak latency instead.
The silent production failure detection is what catches my eye. When you're running AI agents in prod, the scariest failures are the ones where nothing errors out - it just gives bad output for days without anyone noticing. Curious how Cekura handles the baseline drift problem - do you need a human to label 'good' vs 'bad' outputs, or does it pick that up automatically?
Cekura
@mykola_kondratiuk Human labelling is recommended for any metric you define - you label only 20 calls in our optimizer to ensure the LLM-as-a-judge covers all the edge cases
20 calls to bootstrap the judge is surprisingly low - that's actually pretty approachable for most teams. The LLM-as-judge approach makes sense for scale once you've got those calibration samples.
Cekura
@mykola_kondratiuk Human labelling help fine tune the metric and make it highly accurate for the good/bad identification. And at scale this metric then goes on and evaluate 1000s of calls with very high accuracy
Right - the labelling bootstraps the judge, then the judge scales. Makes sense as a two-phase approach.
Cekura
@mykola_kondratiuk Exactly!
glad it landed well. good luck with the launch!