
Agentmemory
Persistent memory for Claude Code, Codex & coding agents
573 followers
Persistent memory for Claude Code, Codex & coding agents
573 followers
You can now give Hermes, Claude Code, and Codex infinite memory. Agentmemory is trending on GitHub with 5,000+ Stars. CLAUDE md dumps 22,000+ tokens into context at 240 observations agentmemory: 1,900 tokens. same observations. 92% less. At 1,000 observations, 80% of your built-in memories become invisible. agentmemory keeps 100% searchable. benchmarked on 240 real coding sessions → Up to 95% fewer tokens per session → 200x more tool calls before hitting context limits → 100% open source




Agentmemory
Hey Product Hunt 👋
I built AgentMemory because coding agents still have one painful limitation: they forget between sessions.
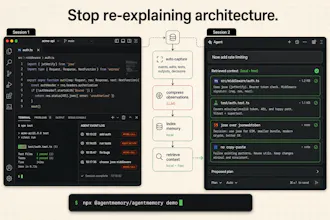
You explain your architecture once.
You debug a production issue once.
You decide on a library or pattern once.
Then the next session starts from zero again.
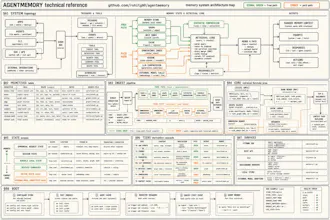
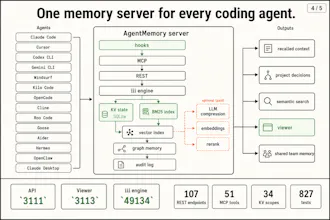
AgentMemory gives AI coding agents persistent memory across sessions, so they can actually build on what they’ve already learned about your codebase. It automatically captures what your agent does, compresses it into structured memories, indexes them with hybrid search, and injects the right context back into future sessions.
It works with Claude Code, Cursor, Codex CLI, Gemini CLI, Windsurf, Kilo Code, OpenCode, Cline, Roo, Goose, Aider, Hermes, OpenClaw, and basically any MCP or REST-capable agent.
From day one, I wanted it to be:
100% open source
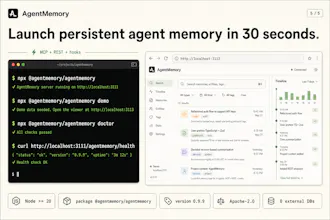
Free to run locally
No external database required
Works via MCP, REST, and simple hooks
Built for real coding workflows, not toy “chat history” memory
On benchmarks, AgentMemory gets 95.2% R@5 and 98.6% R@10 on the LongMemEval-S retrieval suite using BM25 + vector search, while cutting context usage by around 92%.
Quick start:
Open: http://localhost:3113
Or try the demo: npx @agentmemory/agentmemory demo
If you live in your coding agents every day, this is for the moment you think: “Wait, I already explained this yesterday.”
Would love feedback from builders, heavy agent users, and open‑source maintainers.
GitHub: https://github.com/rohitg00/agentmemory
@agentmemory @rohit_ghumare How do you think about secrets or sensitive data accidentally entering memory? Is there filtering/redaction built in, or do you recommend teams handle that at the hook/integration layer?
OpenHuman
well done @rohit_ghumare i'd love to know what's the business model you intend to persue? looks like everything is free and opensource. just wondering would u be making this a hobby project or building it seriously or something else?
Agentmemory
OpenHuman
@rohit_ghumare mashallah, i wish you guys more success :D :D we're going to natively integrate this into OH
Agentmemory
Persistent memory for coding agents is a harder problem than it sounds. You're not just storing conversation history, you're storing codebase context, decisions made, patterns established. The benchmark claim is what I'd want to dig into. Memory that's fast to write is useless if retrieval is noisy. How does it handle context that's become stale after a refactor?
Really interesting, can it pick up past sessions or does it start only once i integrate? On another side note is there a way to not use an agentic db and maybe postgres?
Great traction! I will give it a try on my current project and see if it brings down hallucination. I like the graph view so you can easily see whats going on.
Just wondering how long did this take to make? The database side is very interesting and i think has a lot of potential to many other things. Good luck!
Agentmemory
The cross-session forgetting problem is real. The deeper one you'll hit at scale: when an agent makes a wrong call in week 4 because it remembered a misleading decision from week 1, where does ownership of that mistake sit? Two questions worth thinking about: 1. Can memory be exported in an open format so agents move with their user, not their runtime? 2. Is there a way to mark a memory entry as disputed or superseded? Without those, an agent's persistent memory becomes a liability dressed as a feature.
Agentmemory
The 92% context compression is the number that actually matters here.. I've run into the CLAUDE.md token dump problem myself where the context window gets eaten before the agent even starts doing real work. The hybrid BM25+ vector search approach makes sense for this use case too, pure vector search misses exact identifier matches which in a codebase is basically everything important.. function names, variable names, file paths.
One thing I'm curious about.. how are you handling memory staleness? If I refactored a module two weeks ago and the old architecture is still in memory, the agent might confidently suggest patterns that no longer apply. Is there a TTL mechanism or does it rely on the agent to overwrite outdated memories when it encounters contradictions? That's the failure mode I'd be most worried about in a real codebase.
Having trouble with large data sets. Just spent a few days stress-testing agentmemory on a real-world workload.
Dataset: ~674 Claude Code sessions / ~370K observations / ~108 hand-curated memories, imported from 1.5 GB of jsonl history across 24 projects.
Graph extracted to ~75K nodes / ~6K edges. All running locally with OpenRouter (Gemini 2.5 Flash Lite for LLM, OpenAI text-embedding-3-small for embeddings).
Bugs hit, all confirmed as open GitHub issues:
- #502 — Graph auto-trigger never fires on session end (the session.stopped topic has no publisher in shipped code)
- #544 — /memories and /export endpoints return 500 on large corpus
- #587/584 — Buffer pool corruption causing worker crash loops (filed today!)
- #474 — agentmemory stop leaves iii engine running with stale function registrations
- #538 — Viewer's "Rebuild Graph" button calls /graph/build which doesn't exist server-side
- #455 — No dimension override means switching embedding models requires AGENTMEMORY_DROP_STALE_INDEX=true (which I learned the hard way actually persisted on every restart in my hacked-together approach)
Workarounds I built: custom hourly LaunchAgent calling /agentmemory/graph/extract directly to compensate for #502; chunked batching (50 obs/request, file-based payload via --data-binary @file) for /graph/extract to avoid "Argument list too long"
Net result: Sessions API + Memories tab work fine, live capture works, recall context injection works at session start (~1300 tokens of project history). The graph viz endpoint times out at our size and the worker crash loop makes things unstable when querying graph-heavy endpoints. LaunchAgent workarounds just caused more chaos, so reverted to started terminal frontend launch/operations to simplify. But the issues remain.
Fortunately, even after wiping and starting over halfway through, the total OpenRouter spend across all this was only about ~$15. The concept and the architecture are solid; the scale-handling needs another iteration or two before it's production-stable for a real coding workflow. Watching the GitHub issues.
Great work, excited to see this puppy land with the kinks worked out! Pausing usage until its a bit further along.