Launched this week

agentbrowse
Give your AI coding agent the web as a command line
79 followers
Give your AI coding agent the web as a command line
79 followers
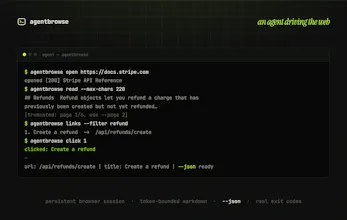
AI coding agents are great in a terminal and clumsy in a browser. agentbrowse turns any website into a CLI they drive it can open, snapshot, click, fill, read as clean markdown, even log in. One command makes Claude Code, Codex, Cursor, Gemini & Windsurf use it by default.



Embedist
the framing of the web as a command line for an agent is powerful because it implies the agent thinks in verbs not pages. curious how auth and session state work in that model. if an agent needs to read something behind a login, does the user grant per site credentials, or is there a more general delegation primitive? that part feels like the unlock for real autonomy.
@thenameisarian FYI
Embedist
@thenameisarian Love this framing, "verbs not pages" is exactly the intent. On auth: agentbrowse is local-first, so the trust model is delegation, not credential sharing. You run agentbrowse login , which opens a real headed browser. You log in yourself once (password, SSO, 2FA, whatever the site throws at you), and only the resulting authenticated session (cookies + storage) gets persisted to disk for headless reuse.
The agent never sees or types your credentials. It just inherits an already-authenticated tab. So the "delegation primitive" you're pointing at is: human authenticates interactively once, agent drives the session that produces. Sessions are isolated and named (--session work, --session personal), so it's effectively per-context scoping rather than one big god-credential. The agent gets a capability (an open, logged-in browser) instead of a secret, which is the boundary I think makes autonomous browsing actually safe.
Hi there,
Turning the web into a command-line interface for coding agents is a neat abstraction. The trust layer seems important though: how do teams verify what the agent actually clicked, whether the page state changed unexpectedly, and whether a snapshot is enough evidence to debug or audit a failed browser workflow?
Embedist
@forest_top Agreed, the trust layer is the whole game. Two things make it auditable today:
1. Every action is an explicit, named command with structured output. click 12, type 1 "...", and each returns the resulting URL + title, so you get a literal trace of what was done and where it landed. snapshot gives you the page state as [ref] role "name" before and after, so you can diff state across a step instead of trusting a screenshot.
2. It fails loud, not silent. If the page changed out from under a ref, the action does not "click something close enough", it returns a stale_ref error and refuses. So an unexpected page-state change becomes a hard signal in the log, not a mystery misclick. That's the thing that makes a failed workflow debuggable: you can see the exact ref that went stale and re-snapshot to inspect the new state.
--json on any command makes all of this machine-checkable for CI/replay. Fuller record-and-replay of a whole run is the direction I'm pushing next, but command trace + snapshot diff already covers "what did it click and did the page change."
is this tool can reuse my login session when open page? or it's like open in stateless
Embedist
@sleekzheng It reuses your login, it's not stateless. Run agentbrowse login once to sign in via a real browser, and that authenticated session persists to disk and is reused by every later headless command. State (cookies, storage) also carries between commands within a session because it runs a persistent background browser. You can keep multiple isolated logins side by side with --session . So "open page already logged in" is the default behavior, not the exception.