Launched this week

MindReader v1
Read minds (simulated fMRI data, channeled to neuro-metrics)
191 followers
Read minds (simulated fMRI data, channeled to neuro-metrics)
191 followers
How do you feel? It is the oldest question in art and the newest one we can answer in technology. MindReader takes your content and simulates, region by region, how a brain responds to it. Completely Open Source - we encourage you to tinker. Exploring sales evals, neural evals for datasets and other esoteric product experiments w/ madhat founders. MindReader is built on Meta FAIR's TRIBE v2 + 35yrs of neuro research. Inviting collab from the academics et all.











MindReader v1
One concern I have is overinterpretation. users might treat simulated neural outputs as scientific truth, so clear framing and limitations will be important.
MindReader v1
@malani_willa we completely agree! Which is why we chose to build in a completely open source manner. We want to strengthen these metrics, test them rigorously before pushing them to consumer products.
Clear communication and community accountability is a core part of our DNA. Appreciate the flag.
@ishita8088 Hi, Tried the product at the trial setup page and honestly the experience felt like stepping into a neuroscience lab 😄 The visualizations are fascinating and definitely spark curiosity. At the same time, I found myself wondering how much of the report reflects real cognitive signals versus an interpretive model. Either way, it's a very memorable experience and a fresh way to think about message analysis.
MindReader v1
@harini_mukesh really appreciate the note. the UI/UX is us leaning into the sci-fi world on purpose- the product's inspired by a lot of sci-fi stories we love.
on your actual question, real cognitive signal vs interpretive model- it's both, and worth separating.
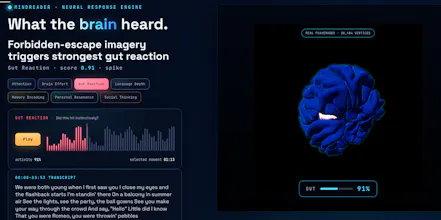
the brain map is a prediction from TRIBEv2, which is trained on ~1,000 hrs of real fMRI, so the regional activity you're seeing is grounded in real scan data, not invented.
the interpretive part is the layer on top: the 7 signals and scores like Personal Resonance 0.85. that's us mapping predicted activity in known regions to named functions, based on published research, then normalizing the output. so the activity is modeled from real brains; the labels are our reading of it.
that's exactly the layer we open-sourced- it's the part worth poking holes in.
PS: @jas_jaski actually has a '42' tattoo; v. devoted sci-fi fan
Simulating how a brain reacts to content is a fascinating concept, and love that it's open source. How accurate are the neuro-metrics compared to real fMRI studies?
MindReader v1
@doganakbulut good question, and the honest answer is it's a prediction, not a measurement. TRIBEv2 doesn't read a brain. It predicts the fMRI response an average brain would produce, trained on ~1,000 hrs of real scans across 720 subjects. Meta reports 2–3x better accuracy than prior encoding models, and zero-shot correlation around 0.4 on subjects it's never seen. So: good, not gospel.
What that means in practice one should trust it for relative signal (where attention holds vs. drops inside one piece of content) far more than absolute numbers.
The 7 signals sit as an interpretive layer I built on top of the voxel predictions, mapped to published region → function research. That layer carries its own assumptions, which is exactly why it's open source - so peers can audit / tweak it.
MindReader v1
@mdgld so the platform runs your content second by second and pulls the top 3 moments where a signal spikes. so instead of "here's the gut reaction region," you get a snippet like this:
Open areas of conversation / areas we are keen to explore further:
neural-tags for dataset (voice in particular)
evals
content / sales / coaching
d: <enter your answer>
looquee
congrats on the launch! super interesting ideas. I wonder what you use as a proxy for attention. Do users need to give inputs or do you estimate where the users might be focusing on based on moment-to-moment 'salience'?
looquee
I also wonder whether your model also uses E/MEG data, because the simulation seems to be a stretch of fMRI's temporal resolution
MindReader v1
@looquee_26 ty for the questions.
there's no user in the loop. we take the content itself and simulate how an average brain would respond to it. so "attention" here isn't where someone's eyes go - it's what the content does to a specific network in the brain. and it's not the grab-your-eye kind (the salience you mentioned), it's the goal-directed kind, the focus you actually give something. that's the dorsal attention network, modeled from TRIBEv2.
full mapping's here: mindreaderai.vercel.app/methodology
second one - it's fMRI-only, no E/MEG. fMRI reads blood flow, so the timeline runs on a few-second grain, not milliseconds. the "second by second" is the rate we output a number - we're modeling how the response builds over a stretch of content (ideal inputs at least 20-30s long). that few-second grain is the right resolution for what we are experimenting around: where a pitch holds vs drops across a minute.
simulated fMRI is an interesting framing because it lowers the barrier from clinical setting to anywhere with a laptop. curious which use cases you're seeing pull on this first. is it more researchers doing prototype experiments before booking real scanner time, or builders putting brain inspired models inside consumer apps?
MindReader v1
@thenameisarian the most interesting use case I'm seeing is in sales. because there is a lot literature + clean datasets around sales call evals already - it is fun to start testing a lot of h0s in the real world.
we are experimenting with an SF-based voice AI team that is feeding their own agent's sales-call data through MindReader to get a signal for what does a "good call" mean.