Launched this week

Replicas
Run Claude Code and Codex in the cloud
344 followers
Run Claude Code and Codex in the cloud
344 followers
Run background coding agents from anywhere. Spawn Claude Code or Codex in a VM with code and tooling ready to go. Hand off tasks from Slack, Linear, or GitHub Replicas runs Claude Code, Codex, or any coding agent in the cloud. Agents run in isolated VMs with real dev environments, and you can bring your own subscriptions and API keys. Trigger tasks from Slack, Linear, or GitHub and come back to a PR ready to review.





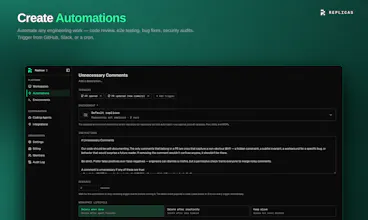



Free Options
Launch Team / Built With


Replicas
The cloud VM approach makes sense especially when multiple agents need to run in the background without depending on someone's laptop. How does Replicas handle conflicts when two agents are working on related parts of the same codebase?
Replicas
@ada_johnsen Hey Ada! Totally agree. The first take here is that AI agents have made dealing with merge conflicts a much easier game. Replicas actually has a built in feedback loop, where it automatically reacts to CI failures, code reviews, and in this case merge conflicts. This means that two different agents will resolve automatically with zero human friction.
Additionally, complete isolation means these agents can test changes end-to-end without conflicts, until they're ready to merge.
Spawn Claude Code in a VM with tooling ready to go, this is genuinely what I keep wishing existed when I'm
delegating background tasks. I build entirely through Claude Code today and the friction is exactly what
Replicas is solving, I guess.
How do you handle long-running agent sessions that need to wait for human input (a question that needs answering
mid-task)? Does the VM pause and resume, or does the agent post the question and continue with what it can?
Congrats on the launch.
Replicas
@erginmurat The VM will stay awake for 30 minutes of inactivity, and the UI visually indicates to the user that input is needed. But if there's a long wait, you can easily wake it up later on and pick up where you left off!
Mailwarm
Do you support switching models per task, like Claude for refactors and Codex for quick fixes?
Replicas
@othman_katim Absolutely! For any chat you can switch models / agents.
Dart
Congratulations on the launch!
We use replicas in our day-to-day work to develop multiple features in parallel. It also enables us to do multiplayer, where the product and engineering teams hand off the session back and forth as the development progresses.
We absolutely love the fact that it doesn't lock us into a bad in-house harness, since they just allow us to use the ones from big AI labs. This is a huge benefit, because it means the features that the labs come up with are available right away — we don't have to wait months for the in-house harness to catch up. Another super nice thing is that we're able to preview the work live directly in Replicas via remote desktop or use SSH.
Cloud agents are the next big thing in the AI coding world, and Replicas is the best one out there right now. Excited to see where it ends up!
Replicas
@nevecex Thanks Ivan, its been amazing building Replicas for the team!
Isolated VMs per agent run is the right model for correctness. It eliminates state bleed between runs and makes failures clean to recover from. We've hit friction with stateful runners where a mid-task failure left dirty workspaces that blocked the next run entirely. How do you handle dependency caching across VM instances when agents need to install packages mid-task?
The "agent stops the moment you close your laptop" framing is spot on — the clamp-to-keep-your-laptop-open line made me laugh because I've literally done that 😅
The question I keep landing on with background fleets: once agents are shipping PRs around the clock, the bottleneck quietly moves to review. Ten parallel agents is ten PRs a human still has to read and trust. You mentioned personalized code review and auto quality checks as use cases — is the long-term play that Replicas agents review each other's work, so the human is approving a verified diff instead of reading every line? Or do you still see a human gate on every merge?
Curious where you think the trust boundary settles. Congrats on the launch 🚀