Gemini 3.1 Flash-Lite runs tool calling, classification, translation, and multimodal processing via API on Google's Gemini Enterprise Agent Platform. For AI engineers building high-volume, latency-sensitive agent pipelines in production.
/monitor by FirecrawlNotify your AI agent when the web changes
Promoted
Hunter
📌
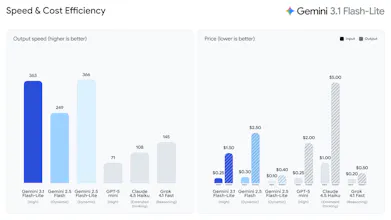
Google’s most cost-efficient Gemini 3 model just hit GA, and the production numbers are worth watching.
Gemini 3.1 Flash-Lite is Google’s fastest and cheapest Gemini 3 model, built for high-volume AI workloads where latency and cost matter more than deep reasoning.
Most production AI isn’t “thinking.” It’s classification, routing, translation, moderation, and orchestration at scale. That’s exactly where Flash-Lite fits.
Key highlights:
Optimized for tool calling and agent orchestration
Multimodal text + image support
Sub-second p95 latency for structured tasks
~1.8s p95 for full responses
~99.6% success under heavy concurrent load
Significantly lower inference costs vs reasoning-tier models
Gladly reportedly cut costs by ~60%, while OffDeal used it for real-time responses during live investment banking Zoom calls.
The bigger question: does AI infrastructure permanently split into reasoning models and execution models — and does Flash-Lite become the default execution layer?
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified →@rohanrecommends
What makes GA so different from preview access, just stability? I suppose this post is saying “our model is now ready for use in production applications” which i suppose is fair but not the most exciting for hackers and tinkerers like those on Product Hunt. Feel free to reply me if you feel there’s something I’m not seeing.






 OpenAI
OpenAI
Google’s most cost-efficient Gemini 3 model just hit GA, and the production numbers are worth watching.
Gemini 3.1 Flash-Lite is Google’s fastest and cheapest Gemini 3 model, built for high-volume AI workloads where latency and cost matter more than deep reasoning.
Most production AI isn’t “thinking.” It’s classification, routing, translation, moderation, and orchestration at scale. That’s exactly where Flash-Lite fits.
Key highlights:
Optimized for tool calling and agent orchestration
Multimodal text + image support
Sub-second p95 latency for structured tasks
~1.8s p95 for full responses
~99.6% success under heavy concurrent load
Significantly lower inference costs vs reasoning-tier models
Gladly reportedly cut costs by ~60%, while OffDeal used it for real-time responses during live investment banking Zoom calls.
The bigger question: does AI infrastructure permanently split into reasoning models and execution models — and does Flash-Lite become the default execution layer?
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
Ideaflow
Amazy.uk
mailX by mailwarm
Congrats. Amazing launch!!