
Launching today

Claro
Claro runs the AI agents that operate on your data
55 followers
Claro runs the AI agents that operate on your data
55 followers
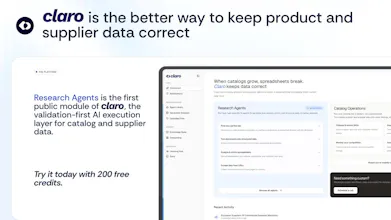
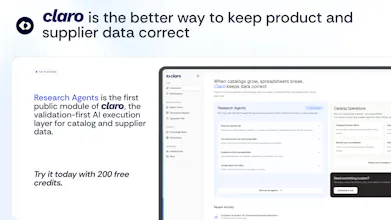
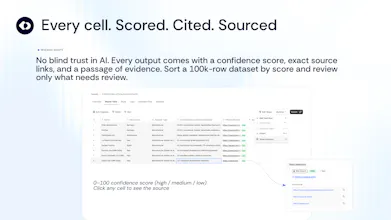
Today, we're opening the first public module of Claro: Research Agents. 10+ task-specific agents run inside a native table - enrichment, PDF extraction, URL scraping, classification, location lists, dedupe. Every cell comes back with a confidence score, citations, and ranked sources. Built validation-first, not a chat wrapper. 200 free credits on signup, no card.







Claro
Hey Product Hunt 👋 I'm Matteo, co-founder of Claro.
We built Claro because we kept losing trust in our own AI outputs. @tameesh and I spent years at Delivery Hero and Yelp trying to wrangle product and supplier data at scale. Tameesh then did NLP/LLM research and published at MIT Review. Every time we plugged an LLM into a data workflow, we got beautiful-looking answers with no way to know which ones were right.
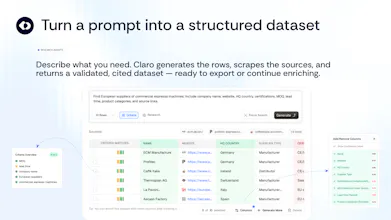
Claro is the AI execution layer for product and supplier data. It takes messy supplier feeds, spreadsheets, and documents, turns them into trusted catalog entities with stable IDs, and keeps them validated and correct over time.
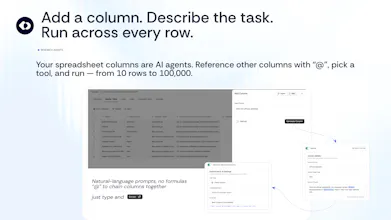
Today we're opening the first public module: Research Agents. 14 task-specific agents that run inside a native table:
📋 Find your perfect list — describe ideal prospects, suppliers, or partners, get an enriched dataset 📍 Build a location list — draw an area on a map, generate POIs with attributes 📄 Capture tables from PDFs — pull tables from reports, pick which to keep 📑 Turn documents into structured data — extract fields across hundreds of docs at once 🌐 Scrape data from URLs — turn a list of links into structured rows 📊 Analyse CSV — upload a spreadsheet, validate and enrich it 🔀 Merge & Map — dedupe and reconcile records across two files and more.
What makes Claro different is what happens to every answer before it hits your table:
→ Multi-model consensus — we push extractions to multiple models in parallel and only accept where they agree
→ LLM-as-judge filtering — a lightweight quality gate catches nonsensical outputs before they reach you
→ Source ranking — first-party and authoritative sources above random blog posts, datasheets above application guides
→ Confidence scores — every cell scored at row, column, and entity level based on source reliability, cross-source consistency, model certainty, and retrieval quality
→ Full citations — click any cell to see the exact passage, URL, or document section it came from
→ BM25 + AI hybrid matching — for entity resolution against your existing catalog, with human approval loops for borderline cases
It's not a chat wrapper. It's validation-first infrastructure with a spreadsheet you can use today.
Three things I'd love today:
Try it — 200 free credits, no card.
Break it — throw your ugliest CSV or weirdest PDF, tell me what it got wrong (and what the confidence score said)
Tell me which agent you'd use first — we're deciding what to deepen next
I'm pitching live at The Pitch Berlin today, so I'll be bouncing between stage and comments, but I'll reply to every one before EOD.
If you run a marketplace, distributor, or multi-supplier catalog and the underlying platform sounds relevant, DM me — we'd love to talk.
Thanks for taking a look 🙏 — Matteo
Claro
thanks @rajiv_ayyangar for the support as Hunter!