
TryCase
Disposable test environments for AI coding agents
289 followers
Disposable test environments for AI coding agents
289 followers
TryCase gives AI coding agents disposable Linux environments to run apps, test changes end to end, capture screenshots and recordings, and return verified code instead of asking you to test manually.



Hey Product Hunt,
I’m Ben, and I’m building TryCase.
This came from my own workflow. I’ll often have a bunch of agents running at once across different worktrees, each trying changes, spinning up the app, testing, iterating, taking screenshots, or recording proof.
That gets messy quickly. My laptop becomes the bottleneck, ports collide, installs overlap, browser sessions get reused in weird ways, and I still end up doing a lot of the final verification myself.
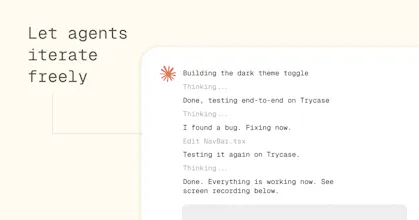
So I built TryCase to give each agent its own disposable Linux environment in the cloud. The agent can run the app, test the change end to end, capture screenshots or video, and come back with proof instead of just code.
It’s also useful for longer-running tasks. You can give an agent a goal, let it work inside a clean disposable environment, and ask it to come back with screenshots, logs, and recordings. Secrets can be passed in deliberately, and each run is isolated from your laptop and from other agents.
TryCase is still early, but the goal is simple: agents should only say “done” once they’ve actually run and verified the work.
It’s easy to try. Just ask your coding agent to use TryCase at trycase.dev:
- Fix this bug, test it end to end with TryCase, iterate until it works, and send me screenshots and a video recording as proof.
- Implement this feature, run the app in TryCase, iterate on any failures, and prove it’s working with screenshots, logs, and a recording.
- Use TryCase to run this repo in a clean environment, verify the main flow, and show me what the app looks like.
- Test this branch in TryCase, find anything that breaks, fix it, and prove the final version works.
- If manual login is needed, use desktop mode and give me the take-control link.
I’d love feedback from people using Codex, Claude Code, Cursor, or other coding agents. What would make you trust an agent’s “done” more?
"agents should only say done once they've actually run and verified the work" is exactly right and it's the thing i keep running into with my own multi-agent setups - an agent will confidently report success based on its own transcript when the thing it was supposed to do never actually happened underneath. running multiple worktrees locally does turn into port collisions and reused browser sessions pretty fast like you said. does the screenshot/recording proof get attached anywhere the agent itself can't fake or reword, or is it still on me to actually look at the video rather than trust the agent's summary of it?
@omri_ben_shoham1 Screenshots and recordings can be downloaded from the CLI, but someone still needs to verify them. In my workflow, I usually have an agent handle the verification, and then I quickly skim through the recording it surfaces.
So far, I've found GPT-5.5 to be pretty reliable for this.
I'm curious what your ideal workflow would look like. Right now, Trycase is intentionally minimal and only exposes tools that agents can use. It doesn't have its own built-in agent yet, so it relies on whatever agent you're using.
@ben_chomsang Could you please add the recording and screenshot review process to the AI? The AI should verify whether they are correct, and if it finds any issues, it should retry the task automatically.
In Agent AI, there are a large number of screenshots and recordings, so manually reviewing each one is very time-consuming. Adding this capability would make your product much more useful and efficient than it is now.
@niravpl41 Thanks, that’s a helpful point. I’m still figuring out what the right verification loop should look like. When you imagine the AI reviewing screenshots and recordings, what would you want it to verify specifically? The visual result, the full user flow, or whether the outcome matched the original task?
If the AI is uncertain, would you want it to retry automatically or ask for a human review?
@ben_chomsang When you imagine the AI reviewing screenshots and recordings, what would you want it to verify specifically? -- AI will check the like if any ui error like checkbox mis configured or any related to ui.
The visual result, the full user flow, or whether the outcome matched the original task? -- the last file updated by ai.
If the AI is uncertain, would you want it to retry automatically or ask for a human review? -- no human review, fully auto.
Screenshots and recordings as verification artifacts are useful for UI changes, but for backend logic or API behavior the visual output doesn't tell you much about whether the code actually works correctly. What does TryCase return as verification evidence for non-visual changes, like a database write, a webhook handler, or a background job, and how does the agent know the difference between "it ran without error" and "it did the right thing"?
@ansari_adin That’s a fair concern. Today TryCase gives the agent access to terminal output, logs, files, browser network data, and other artifacts, not only screenshots and recordings. But deciding whether that evidence proves the correct behavior still depends on the agent and its instructions.
For PR-based QA, I’m considering having one agent generate temporary scenarios and tests, then a separate agent review the results and evidence. For non-visual changes, what evidence would you trust most? Database and API assertions, structured logs, event traces, or something else?
@ben_chomsang Database assertions and event traces are the right answer for most backend verification, but they require the agent to have a model of what the expected state should be after a given operation, which is the part that's actually hard. How are you thinking about getting that expected state into the verification loop, is it inferred from the code change, pulled from existing tests if they exist, or does the developer need to describe the expected behavior explicitly before TryCase can verify it?
@TryCase Giving coding agents an isolated, disposable Linux sandbox is exactly how we solve the local port collision and dependency nightmare. Since TryCase is exposed as a runtime tool layer for external agents, how are you handling base image caching? If an agent executes a massive npm install or updates a database schema across multiple iterative debugging runs, do you snapshot and delta-cache that specific container's filesystem state, or does it do a clean cold boot every time the agent invokes a test call?
@puneeth_b1 Great question. The same environment stays alive across the agent’s iterative commands, so installed dependencies, build caches, files, and database changes persist during that run. We do not cold boot a new environment for every test call. A newly created environment starts clean.
The host caches the base guest image, and each environment gets its own writable filesystem. We do not currently create reusable project-specific dependency snapshots across separate environments.
Is your main concern speeding up repeated attempts within one PR run, or reusing dependencies across later runs for the same repository?
the 'done only after it actually ran and verified' bar is the right one. do you surface the failed attempts too, or just the final passing proof?
@andrewzakonov Right now, this depends on the agent deciding what to keep track of. For example, if it's instructed to record failed attempts, you'll be able to review the full history of runs and their artifacts. My goal is to keep the tool flexible by providing a small set of focused commands that the agent can use as needed. I'm curious if you think this is the right approach, or if you'd prefer a single tool that always behaves the same way and handles everything for you?
Such a smart concept for vibe coding. Testing AI-generated code safely without messing up my local environment is always a massive concern. Can these disposable environments be spun up locally, or is the platform entirely cloud-based?
@doganakbulut Thanks Dogan. TryCase Cloud environments run in the cloud today. There is a self-hosted path for development and private deployments, but it is not yet a simple, polished local runner that you can start through the hosted product.
What would make local execution important for you? Keeping code and data on your own machine, reducing cost or latency, or using your existing hardware?
congrats on the launch ben. the port collision thing you describe hit me the first time i let two agents run dev servers at once, so the throwaway box approach makes a lot of sense. one thing i'm curious about: booting an app end to end usually means real env vars, api keys, db urls. where do those secrets live while a sandbox runs, and does teardown wipe them for good?
@vollos Good question. Today secrets are project-scoped, encrypted at rest, and write-only to users. They can be injected into the environment as variables, generated dotenv files, or setup hooks. TryCase also redacts known secret values from logs and command output.
Destroying an environment removes its writable filesystem and the copies used inside that environment. The encrypted project secret remains available for future runs until the user deletes it. Teardown also cannot remove anything recorded by an external API or database.
For PR-based QA, would you prefer credentials to be temporary for each run by default, or reusable across runs for the same repository?
@ben_chomsang good that write-only plus stripping secrets from the logs is already the default; those two are where this usually leaks in practice. on your question: i'd keep ephemeral per run as the default, pointed at a seeded test resource rather than the real one. it's a blast-radius thing. a per-run credential dies with the box, so a leak or a dumb agent move stays contained, but a reusable repo-wide one turns a single bad run into standing access to whatever it could reach. reusable is nicer DX for fast repeated PR QA, so maybe offer it as opt-in per repo with throwaway staying the default. the setup that'd bite is a reusable credential pointed at a real database instead of a disposable copy.